

Rethinking the Localization Industry: What LLMs Will Really Change
LLMs reshaping localization—beyond segmentation and translation. Why AI models matter less than the assistants built on top. Building durable AI product strategies in a crowded market.

Ciao
In recent months, I’ve noticed a shift in how we talk about AI adoption. We’ve moved past the initial excitement of flashy demos to a point where the central question is no longer “what can a model do,” but “what does it actually change in processes and organizations?”
In this issue, I start from an industry I know well—localization—to show how Large Language Models are not just improving translation but challenging the very operational mechanisms the sector has relied on for decades. From there, I’ll broaden the lens to a more general theme: why, beyond the differences between models, the real turning point lies in the assistants built on top of them and their ability to integrate into real workflows.
Nicola
Table of Contents
Signals and Shifts - Rethinking the Localization Industry: What LLMs Will Really Change
Understanding AI - How LLMs Work and Why AI Models Matter Less Than We Think
Curated Curiosity
How to Build an AI Product Strategy That Stands the Test of Time
Signals and Shifts
Rethinking the Localization Industry: What LLMs Will Really Change

Over the past three years, I have served as the head of the enterprise platform at Translated, a Rome-based language service provider (LSP) with a turnover of approximately €70 million in 2024.
For those less familiar with the term, language service providers specialize in organizing and delivering translation and localization services at scale. In practice, they receive content from clients, break it into manageable units, and distribute it to a global network of freelance translators. Their core strength lies not in translation per se, but in the ability to coordinate complex workflows, enforce consistent quality standards, and ensure timely delivery across dozens of languages.
My time at Translated coincided with the rapid emergence of generative AI—a topic that, in a short span, has come to dominate discussions well beyond the tech world. Even in the relatively stable field of translation, the advent of Large Language Models (LLMs) has raised fundamental questions about the future of the industry, which until recently had evolved mostly through incremental technological refinements.
One question in particular—although, in my view, a reductive one—has taken center stage: do LLMs represent a definitive breakthrough compared to existing neural machine translation (NMT) systems?
Neural Machine Translation (NMT) engines—such as Google Translate or DeepL—rely on large bilingual datasets and neural networks to generate translations. They are fast, reliable, and generally produce grammatically correct and semantically coherent results. Yet, when faced with nuanced phrasing, shifts in tone, or culture-specific references, their limitations become apparent. Crucially, they operate without any awareness of the broader context in which a sentence appears.
This often leads to translations that sound awkward, overly literal, or inconsistent—especially in more specialized or complex domains. Although recent benchmarks show that LLMs can now match the performance of top-tier NMT systems for many language pairs, the real distinction lies elsewhere. Comparing the two is like comparing apples and oranges: both handle language, but their purpose and capabilities are fundamentally different.
NMTs are built for one task: translating individual sentences. In contrast, LLMs are designed to reason across texts, adapt tone and style, infer implicit meaning, and even restructure entire documents to suit their communicative intent.
LLMs are not just more advanced translation engines—they are horizontal technologies capable of transforming the entire operational fabric of language services.
Their potential extends far beyond text generation. From content ingestion and segmentation to quality control, collaboration, and translator interaction, every stage of the localization process can be rethought. In some cases, these systems may even replace the need for manual coordination altogether, thanks to their ability to understand context, learn from feedback, and operate with increasing autonomy.
Localization in a nutshell
To appreciate how LLMs might reshape the translation industry, it's essential first to understand how a typical localization process operates today.
Consider a company that needs to translate various types of content, such as marketing campaigns, mobile app interfaces, or a knowledge base for customer support. The process usually begins by uploading the source text—either manually or via automation—into a Translation Management System (TMS) such as Lokalise.
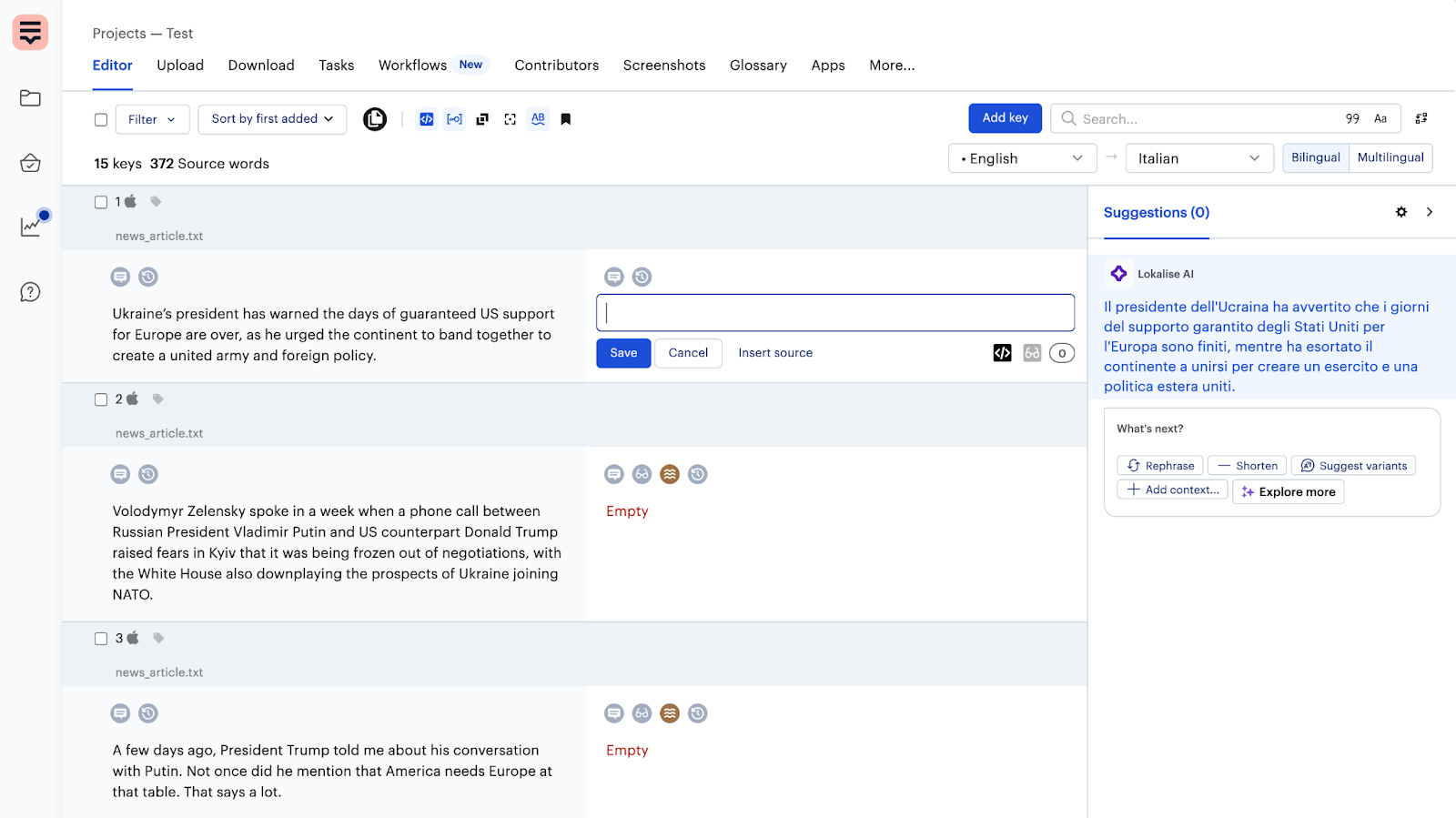
Once the content is in the system, it is segmented—typically at the sentence level—to facilitate more granular management. This segmentation is often complemented by contextual information: screenshots, instructions, glossaries, and style guides are provided to help translators avoid literal translations and maintain alignment with the brand’s tone and identity.
A second core component then enters the picture: the Translation Memory (TM). This digital archive stores all previously validated translations. When the system detects a sentence that matches or closely resembles one already translated, it retrieves the existing version. This reduces both turnaround time and costs while ensuring consistency in terminology and style—especially across repetitive, high-volume content. In e-commerce, for example, a phrase like “Add to cart” may appear thousands of times. Thanks to the TM, it only needs to be translated once.
The company’s internal localization team generally manages these activities. However, if the team lacks its own network of translators, this function is typically outsourced to an LSP, which handles project assignment, review cycles, deadlines, payments, and client communication through a unified interface.
In this sense, the LSP acts as an operational partner, similar to a call center managing customer support or a provider handling payroll services.
At its core, the localization industry relies on two structural principles: segmentation, which helps reduce translation costs, and outsourcing, which shifts the burden of project management to external providers.
These foundational practices—long considered essential for scalability—are precisely what Large Language Models now threaten to upend.
Moving Beyond Segmentation
For years, even as machine translation became a standard component of localization workflows, the segmentation model remained largely intact. Initially, NMT engines were used to suggest translations only when the Translation Memory couldn’t provide a match. This gradually gave way to a practice known as post-editing, where the machine generates a draft and the translator reviews and refines it.
The introduction of LLMs, however, has not changed this logic. Most systems still apply them segment by segment—an approach that, in my view, overlooks the essence of what these models can actually do.
Segmentation was initially introduced to organize human work in an era when translation relied on sentence-level memories and manual input. But LLMs are designed to process and understand full documents, capturing tone, register, narrative flow, and cultural nuance. Fragmenting content into isolated segments strips away the context that makes these systems effective in the first place.
The limitations of segment-based workflows become clear when comparing different types of content. Translating an app interface, a technical manual, or an e-commerce catalog calls for distinct strategies—yet most TMS platforms treat them all the same: as flat lists of isolated strings. What’s lost in the process is precisely what makes a translation effective—its connection to context and communicative intent.
LLMs don’t just allow for a more nuanced approach; they demand it. Instead of applying a one-size-fits-all process, we can now tailor translation strategies to the specific nature of the content. When localizing a mobile app, for instance, I can feed the model the complete list of strings along with relevant screenshots and user flow notes. The result is a translation that recognizes whether a string is a button label, a tooltip, or a system message.
But realizing this potential requires more than just better engines—it calls for a complete redesign of the translator’s experience. Instead of working through isolated segments in a traditional interface, translators should be able to interact directly with the interface they’re localizing. They should see how strings behave in context, access the reasoning behind each suggestion, and adjust the output based on their own expertise.
With all the necessary inputs provided—screenshots, flows, brand tone, and terminology—a capable model can explain its choices, adapt its logic, and become a true partner in the creative process. Empowering translators with this kind of contextual visibility is not a luxury: it’s the only way to unlock the full value of LLMs.
Shifting the Focus
The move from sentence-level translation to context-aware workflows points to a broader misconception that has shaped the industry’s approach to AI. For too long, the industry has focused on the wrong question: Can machines replace human translators?
In the early days of neural machine translation (NMT), this framing made sense. The systems were narrow in scope, built to produce functional translations quickly and at scale. In many contexts, a “good enough” translation—clumsy but intelligible—was preferable to nothing at all. We’ve all seen this logic in action: think of product listings from overseas sellers on Amazon. The language may be awkward, even baffling at times, but it still helps users make a basic decision.
LLMs, however, shift the discussion entirely. Think of a scenario where I need to adapt a health-related article for an Italian audience. It’s not enough to translate words—I need to verify if the medical guidelines cited are valid in Italy, whether the referenced medications have local equivalents, and if cultural sensitivities around the topic differ. These are research and reasoning tasks that lie far outside the reach of traditional MT engines, but well within the capabilities of a properly configured LLM.
This is where the concept of a linguistic co-pilot becomes essential. Rather than simply optimizing speed or consistency, LLMs can enhance the translator’s decision-making capacity by surfacing relevant information, articulating the rationale behind a translation choice, or proposing culturally appropriate alternatives. In this model, the system becomes a partner—not a substitute—guiding the human expert through a complex landscape of linguistic, cultural, and contextual variables.
Automating the Invisible Work
Beyond translation, a substantial share of localization budgets is absorbed by tasks that have little to do with language: assigning projects to freelancers, tracking progress, coordinating reviews, reconciling file versions, and conducting mechanical quality checks. These activities, though operationally necessary, are often repetitive and cognitively shallow—perfect candidates for automation.
With the emergence of agent-based systems powered by LLMs, it is now possible to rethink these workflows entirely. Intelligent agents can dynamically assign tasks based on availability and expertise, pre-validate files, flag anomalies, and provide translators with clear, contextual feedback—without human intervention.
The outcome is not just greater efficiency, but a realignment of human attention toward higher-order work. As in other industries—such as customer service, where generative AI handles routine exchanges—this shift does not eliminate people; it frees them to focus where they matter most.
Reimagining the Architecture
What emerges is that LLMs are not simply the next step in an ongoing evolution. They are a structural break—one that demands we rethink not just the tools we use, but the very architecture of localization: its workflows, roles, interfaces, and assumptions.
And if history is any guide, the most radical transformations rarely come from within. Incumbents—entrenched in legacy systems and sunk investments—often struggle to abandon familiar paradigms. Kodak invented digital photography, but couldn’t commercialize it. Blockbuster saw the rise of streaming, but clung to physical rentals.
In localization, the risk is similar: that established players will treat LLMs as just another feature to bolt onto outdated infrastructure. But fundamental transformation requires more than retrofitting. It demands that we rebuild—from the logic of segmentation to the interface itself—around the actual capabilities of these new systems.
Those who embrace this shift will not simply optimize costs; they will redefine what language operations can be. A few years from now, we might look back and realize that the question was never whether LLMs could replace translators. The real question was: who had the imagination to use them differently?
Understanding AI
How LLMs Work and Why AI Models Matter Less Than We Think
How does a large language model work? When we send a question to an LLM, the text is immediately broken down into elementary units called tokens. A token can be a whole word, part of a word, a punctuation mark, or even a space. For example, the question “What is the capital of France?” is transformed into a sequence like: “What”, “is”, “the”, “capital”, “of”, “France”, “?”.
Tokens are nothing more than numerical symbols: each token is represented by a series of numbers (a vector) that encodes statistical information about its usage in texts.
Once it receives the tokens, the model tries to interpret the context. But here’s the key: it doesn’t do this by “understanding” the way a human would. It doesn’t know geography, nor does it have memory or consciousness. What it does is compare the sequence of tokens it has received with billions of similar sequences it encountered during training.
In the case of the question “What is the capital of France?”, the model has seen countless similar expressions in its training data:
“What is the capital of Italy?” → Rome
“Capital of Spain?” → Madrid
“The capital of France is…” → Paris
The model, therefore, recognizes that this is a linguistic pattern it has seen before. And this is when it starts generating. At this point, it examines all the tokens it could use as the first word of the answer and assigns each a probability. Based on these probabilities, it selects the most likely token—in our example, “Paris.”
Now the model has the original sequence (“What is the capital of France?”) followed by the first token of the answer (“Paris”), and it repeats the same operation: finding the next most probable token, then the next, and so on, until it decides to stop.
This is the core of how an LLM works: a probabilistic prediction repeated thousands of times, one token after another.
And all this happens without the model having any real understanding. It doesn’t know what a capital is, nor where France is located. More simply, the LLM has observed that when a text contains certain tokens, they are very likely to be followed by others. The result, however, is remarkable: coherent texts, useful answers, and well-structured explanations.
Why are there so many different models on the market? The answer lies in the goals and strategic choices of the companies developing them. Each model family aims for a different balance between speed, depth of reasoning, multimodality, openness, and cost.
Beyond the specific capabilities of individual LLMs, it’s helpful to distinguish between general-purpose models and reasoning models. General-purpose models (also called foundation models) are the all-rounders: designed to handle a wide variety of tasks, from creative writing to translation, from coding to information retrieval. They are optimized to deliver fast, versatile, multimodal responses with a good balance between quality and speed.
Reasoning models, on the other hand, represent a conceptual evolution. They don’t just aim to produce coherent and plausible text, but instead try to “think before answering.” It’s as if they give themselves a few extra seconds to evaluate intermediate steps, improving accuracy in tasks that require logic, math, or structured problem-solving. This is the case with OpenAI’s series (now o3) or Anthropic’s Opus, which are capable of internal deliberation before producing their output.
To achieve this leap in quality, research has introduced several technical innovations:
Chain-of-Thought (CoT): the model is encouraged to explicitly produce a sequence of intermediate steps, as if it were writing out the “workings of the solution” before giving the final answer. This simple technique has proven to significantly improve performance in mathematical and logical tasks.
Zero-Shot CoT and Plan-and-Solve: even without examples, a simple prompt like “Let’s think step by step” can induce the model to reason; in some variations, the model first plans a strategy and then executes it.
Tree-of-Thought (ToT): instead of following a single linear chain, the model explores multiple reasoning paths as in a decision tree, discarding those that don’t lead to an effective solution.
Self-consistency: the model generates multiple chains of thought and selects the most common conclusion, reducing random errors.
Reflection and feedback: the model reviews and evaluates its own intermediate outputs, in a rudimentary form of “metacognition” that allows it to correct mistakes during the process.
In summary, while general-purpose models are excellent companions for everyday and creative tasks, reasoning models stand out for their ability to tackle problems that require rigor and clear logical steps. They are no longer just generators of plausible text, but tools that deliberately attempt to build an internal reasoning process before speaking.
For a non-expert user, navigating between the various models can quickly become complicated. Each model has its own “character,” its own specialization, and its own cost. Faced with this complexity, the market trend seems to be toward simplification. For example, in August 2027, OpenAI introduced GPT-5, removing—for ChatGPT users—access to all other models. GPT-5 is a unified model capable of knowing when to respond quickly and when to take more time to reflect, providing expert-level answers. The idea was clear: free users from the burden of manually choosing, by offering a system that autonomously decides the most suitable “mode” (fast, deep reasoning, tool usage, etc.), thanks to an internal router.
In OpenAI’s vision, GPT-5 was meant to please everyone, but things didn’t go entirely smoothly. The innovation was met with great frustration from many users. The transition to the unified version immediately removed access to models like GPT-4o, without warning, leaving many users disoriented—especially those attached to GPT-4o’s “warm” tone and personality. Some even described the new version as “colder,” “flatter,” or even like “a stressed secretary” compared to the model they had been using for months.
The backlash on social media and community forums was intense: many were loudly demanding the return of their “old friend.” In response, in the days that followed, OpenAI reintroduced the “older” models for Plus users, while GPT-5 gained new modes—“Auto,” “Fast,” and “Thinking”—to offer greater control and personalization.
Anthropic, for its part, chose to maintain a clear distinction within the Claude family, presenting three models with different roles: Sonnet is described as “our high-performance model, balancing intelligence and speed for everyday use”; Opus as “our most powerful model, designed for complex tasks such as coding, research, and in-depth analysis”; and Haiku as the lightest and fastest, designed to handle high volumes of requests with a focus on speed and efficiency.
Today, we can say that OpenAI, Anthropic, and Google all have models with very similar capabilities. Of course, each has its strengths, but for most everyday uses, the differences are narrowing. For this reason, it makes less and less sense to focus on the “best model”. It becomes more useful instead to look at what truly makes the difference in the user experience: the conversational assistant.
A conversational assistant is not just a chat interface. It’s the set of features that enable intelligent management of context and memory, integration with external tools, reduced hallucinations, and overall more reliable model usage.
Context and memory management, for example, are crucial: a good assistant must be able to remember relevant information across sessions, maintain coherence, and at the same time give the user control over what data is stored or deleted. Equally important is integration with external systems such as CRMs, databases, productivity tools, or document repositories. This is where the assistant shows its real value—not by merely generating text, but by becoming capable of acting on real processes.
Another key element is grounding, that is, the ability to connect responses to reliable sources. An assistant that correctly cites its sources is far more valuable and credible than one that answers in the abstract, even if powered by a “larger” model. The same applies to security and governance: controls on sensitive data, logging, traceability, and the possibility of audits are decisive aspects when it comes to enterprise adoption.
Next week, we’ll dive into how a conversational assistant actually works—and how it helps us manage the dialogue with an LLM.
Curated Curiosity
How to Build an AI Product Strategy That Stands the Test of Time
In the last two years, we’ve seen a proliferation of so-called “AI-powered” products. Yet, in many cases, this simply means adding a generative layer on top of existing workflows. Useful, perhaps. Defensible over time? Not so much.
A recent article published by Miqdad Jaffer (Product Lead @ OpenAI | EIR @ Product Faculty) on The Product Compass outlines five key steps to distinguish a true AI product from a superficial feature.
Define the Core of the Product. AI must not be a decorative layer—it should shape the product’s core value proposition, influence unit economics, and fuel a meaningful feedback loop. Without these elements, you're merely building a wrapper—easy to replicate, easy to replace.
Build a Competitive Moat. There are three main paths. The first is using proprietary data to continuously improve the model. The second is embedding AI directly into real workflows through smart distribution. The third is building trust—assuring users about security, privacy, and governance is a competitive edge in itself.
Find Your Point of Differentiation. There’s no universal recipe. Your edge might lie in deep workflow integration (think Figma), in a guided and structured user experience, in a strong vertical focus (e.g., legal, biotech), or in the ability to attract and activate a product-centered community.
Design with Economic Realism. AI products don’t scale like SaaS. Clear cost models, well-defined guardrails from day one, and thoughtful decisions about product patterns (copilot, agent, augmentation) are all essential. Simply “doing AI” is not enough—you need to do it sustainably.
Scale with Discipline. Start small. Run controlled pilots, measure adoption and costs precisely, and use feedback loops to iterate. This requires cross-functional teams and new roles like eval engineers or trust leads, who bridge technology, product, and social impact.
Read the full article: OpenAI’s Product Leader Shares 5 Phases To Build, Deploy, And Scale Your AI Product Strategy From Scratch
I also wrote about this topic a few months ago, distinguishing between AI Wrappers and Cognitive SaaS: Cognitive SaaS: Building AI-native solutions with lasting competitive advantage